在 S3 上 Partition 是透過資料夾階層來規劃,假設我使用年與月當作 Partition 則S3的資料夾規劃可以參考下圖,有2020一月與二月的資料階層
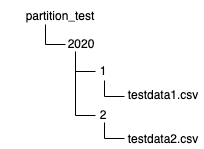
testdata 我是使用 order.csv 平均拆成兩份來模擬兩個月的訂單資料,order.csv 可以到這邊下載
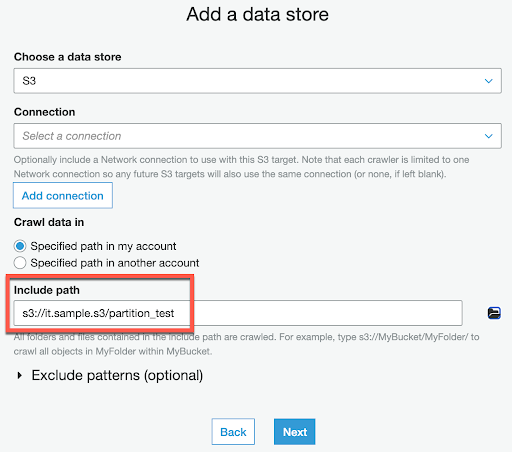
S3 上的資料匯入完成後,再透過 Glue data Catalog 創建虛擬 Table,供 Athena 查詢使用,這部分可參考 Day 5 的做法,需要注意的是 S3 路徑要如下,選擇年的上一層的資料夾
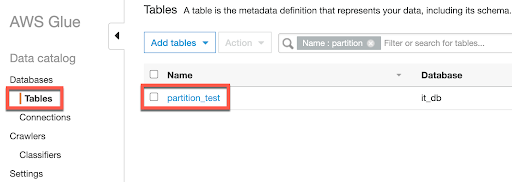
執行 Run crawler 之後可以看到虛擬 Table 中有多了兩個 Partition 的欄位,這些欄位中的值會與 S3 中的資料夾名稱相同,如下圖
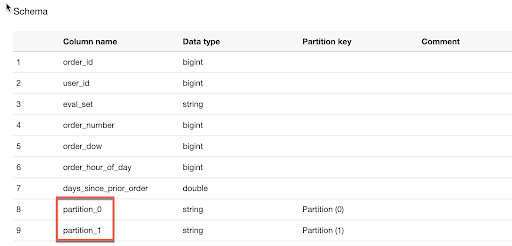
再來我們可以使用 Athena 查詢看看
假設今天我要找出二月的所有訂單,如下圖,可以看到我的查詢量是 52.84MB,而全部訂單的資料大小為 109MB
所以透過 Partition 可以很方便的限制 Athena 所要查詢的範圍,讓 Athena 可以不需要去過濾其他 Partition 的資料,藉此提高效率並降低查詢成本。


 iThome鐵人賽
iThome鐵人賽